Background
A tap reads and processes data from an API or Database. This involves two separate processes:- Discovery: Generating a catalog of the available streams (aka tables), including metadata such as primary keys and available fields
- Syncing: Reading data from streams and writing the resulting records according to the Singer spec
Setting up a local tap environment
Virtual Environments
Dependencies can differ from tap to tap, so it is best to use a virtual environment to isolate the tap’s Python dependencies. You can create a virtual environment named.venv in your tap workspace with:
| Dependency File | Command |
|---|---|
requirements.txt | pip install -r requirements.txt |
setup.py | pip install -e . |
pyproject.toml | pip install -e . |
Config
Both the Discover and Sync processes require a valid config, which will include fields like API keys, OAuth credentials, and configuration flags. For example:
💡 To keep your workspace clean, create a.secretsfolder to store yourconfig.json. Run all tap commands out of this folder to make sure your catalogs and output data stay separate from relevant code.
Using the Hotglue Access Token Endpoint
For OAuth connectors, you can have the tap use the access token endpoint instead of refreshing the token locally by: 1. Adding this flag to yourconfig.json:
| Variable | Description |
|---|---|
TENANT | Your tenant ID |
API_KEY | Your Hotglue API key |
FLOW | The flow ID |
ENV_ID | The environment ID |
TAP | The tap ID (e.g. exact) |
Running a Discover
Within your virtual environment, you can invoke the tap from your command line. For example, if your tap was calledtap-Salesforce, you could run a discover with:
catalog.json with information about the available streams and fields:
Selecting Streams and Fields
The next step of the syncing process is to select which streams and fields you want to sync. We recommend doing this with the Singer-Discover Command Line Utility.catalog-selected.json with:
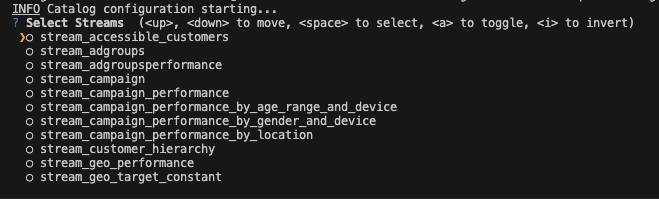
catalog-selected.json that includes your selection metadata.
Running a Sync
You can now sync the streams selected in yourcatalog-selected.json. If your tap is named tap-Salesforce, you could run a sync with:
data.singer file according to the Singer spec.
If you prefer to work with VSCode’s Debugger, you can run a sync with the following configuration: