Connector Details
Credentials Setup
Follow the steps below to get the credentials you need to use the Azure Blob Storage connector.How to get your Blob Storage credentials
The Blob Storage requires only a connection string to connect to your Blob Storage. To find your connection string, log in to your Azure Portal and navigate to your Storage Accounts Dashboard,
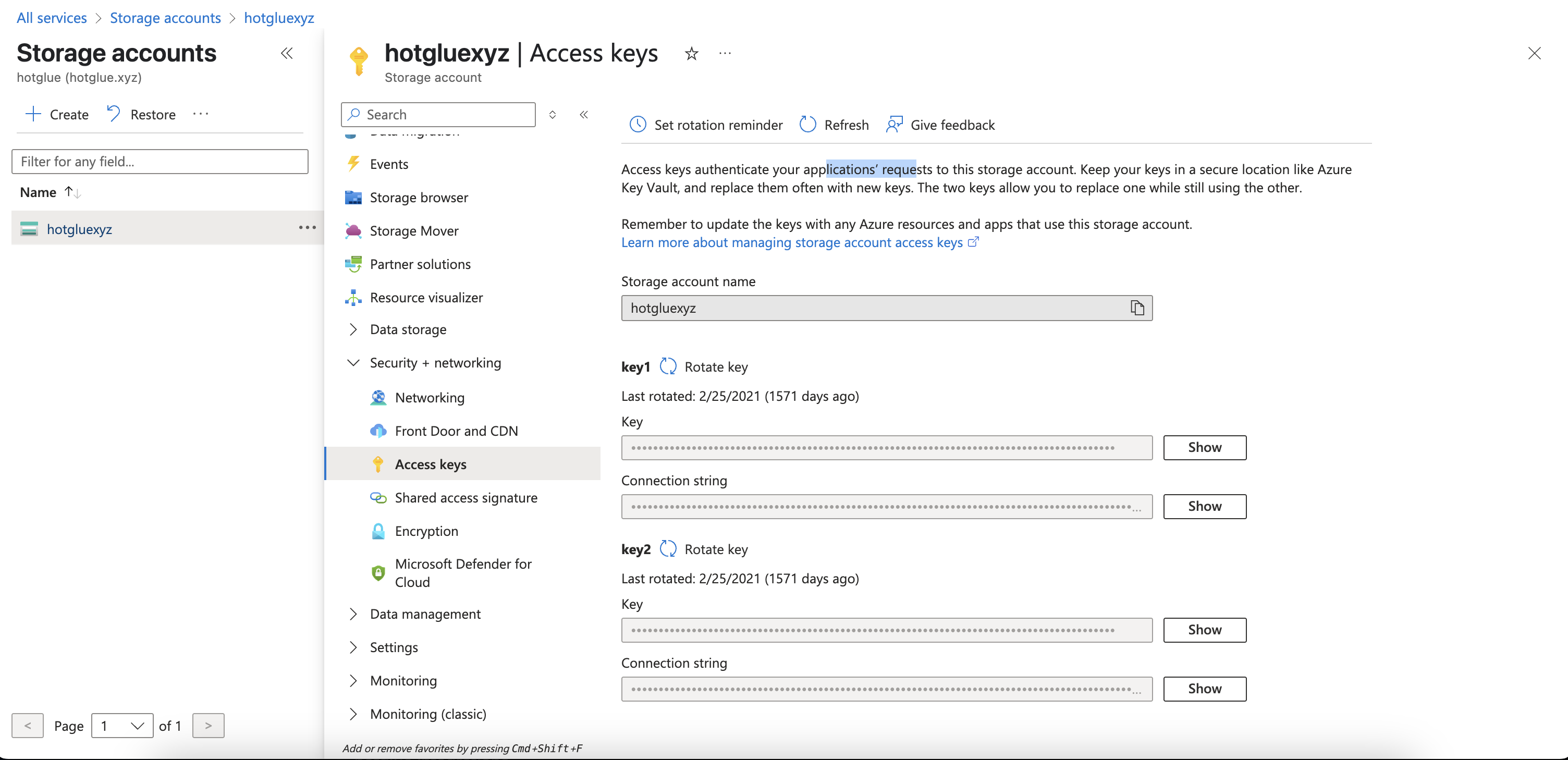
Target Blob Storage
Config
In addition to theconnect_string parameter, you should specify the following fields when connecting:
Example ETL Script
Target Changelog
Target Changelog
Target Changelog