Connector Details
Credentials Setup
The snowflake connector uses the following 8 connection parameters:1. user
If you do not already have a Snowflake account, you can create one here.
 This is the username that should be used when linking the Snowflake connector.
This is the username that should be used when linking the Snowflake connector.
2. account
Once signed in, you’ll be taken to a homepage with a url that looks like:
account field, users should enter “ORG_ID-ACCOUNT_ID”.
For example, if this is your url:
account parameter should be set to rybaofs-ftb21143.
3. warehouse
You can find a list of valid warehouses in Admin > Warehouses
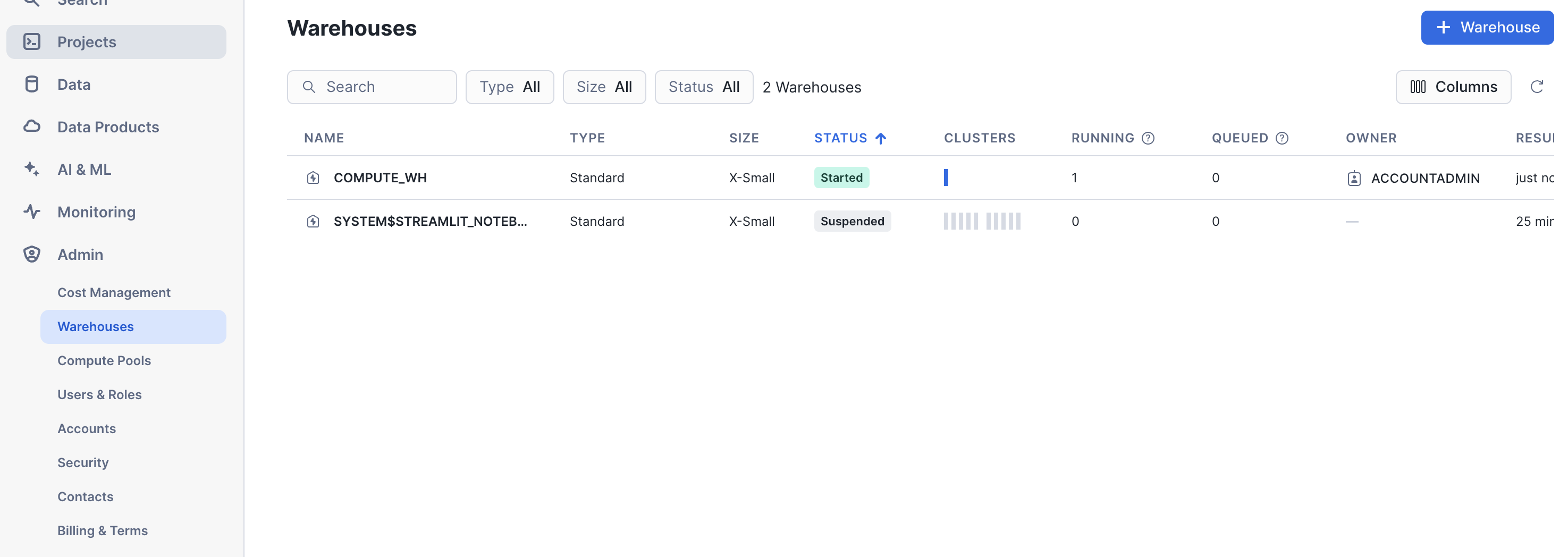
warehouse field.
4. database, and schema
Navigate to Data > Databases, and click the Add Database button in the top right corner.
 You can now create the new database, noting the
You can now create the new database, noting the name:
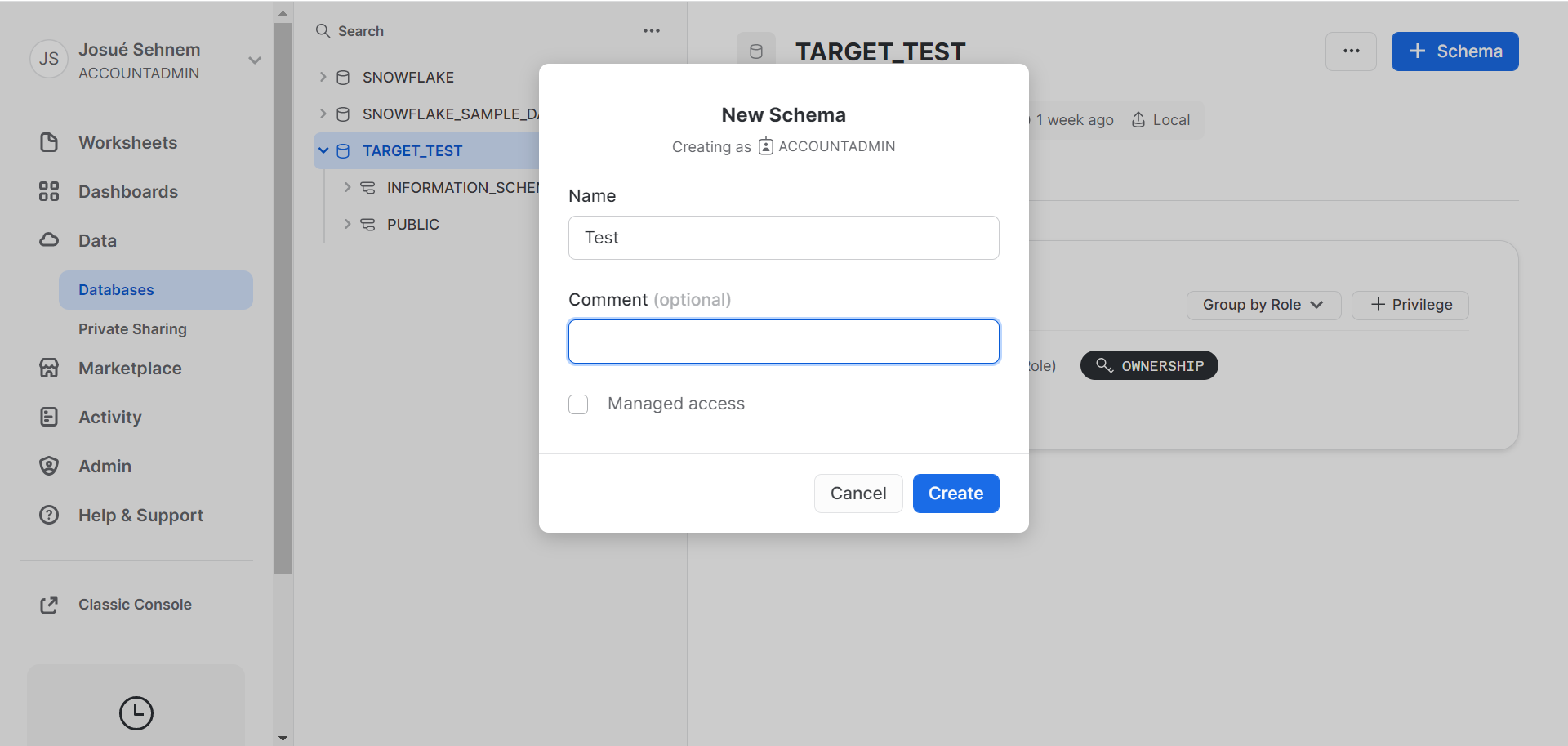 Next, you should search for
Next, you should search for Schema in the secondary navigation bar. You will now be able to see your database name (this example is called Target Test). Within Target Test, you can see the available schemas for this database. Input the desired schema as the schema field in hotglue.
5. file_format
Next, you need to create a named file format in your Snowflake schema.
This will be used by the MERGE/COPY commands to parse the files correctly from S3.
To use CSV files you can create a file format using the command:
file_format_name as the file_format connection parameter.
6. Authenticating with key-pair authentication
Finally, you can generate your private key by running the following command in your local terminal:-nocrypt flag:
private_key_password field.
These commands will generate a private key in the PEM format:
private_key parameter.
Next, generate a public key for your private key with: